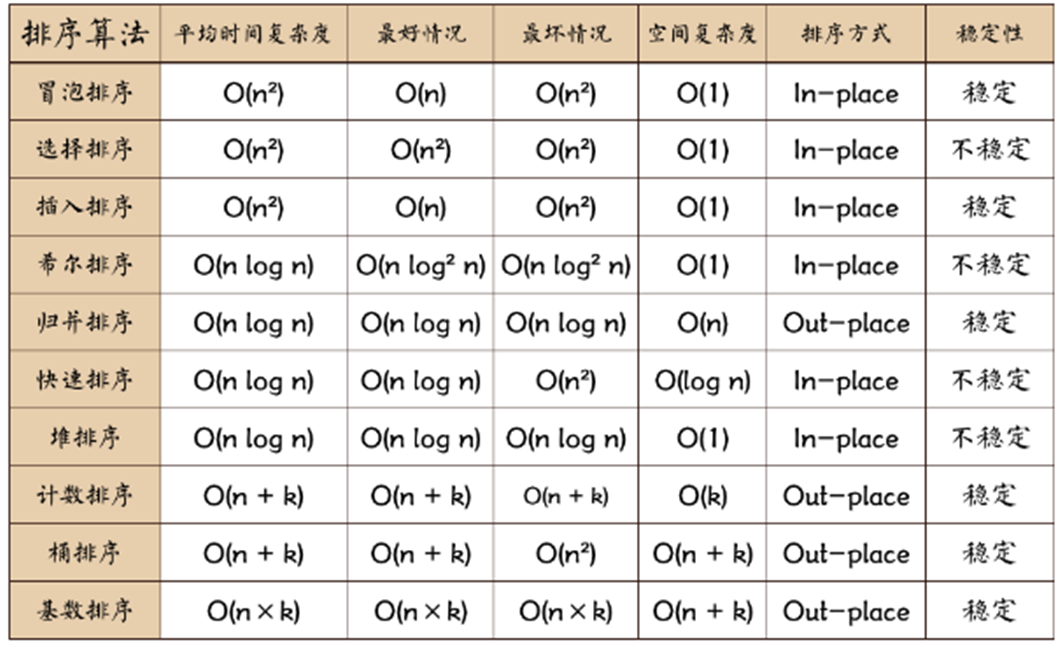
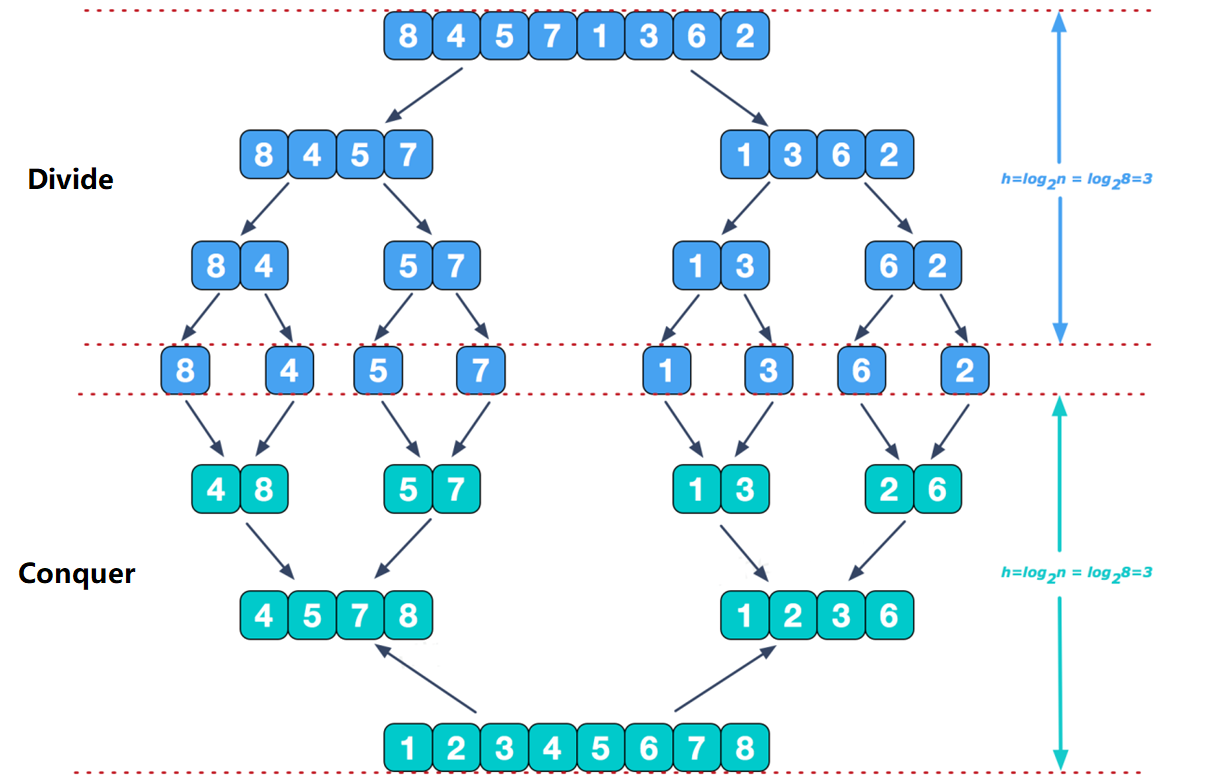
一、基本概念
二叉排序树(Binary Sort Tree, BST)也称二叉搜索树,或是一颗空树,或者是具有一下性质的二叉树:
- 若左子树非空,则左子树上所有结点的值均小于根结点的值。
- 若右子结点非空,则右子树上所有结点的值均大于根结点的值。
- 左、右子树也分别是一颗二叉排序树。
根据二叉排序树的定义有:左子树结点值 < 根结点值 < 右子树结点值,所以对二叉排序树进行中序遍历,可以得到一个递增的有序序列。
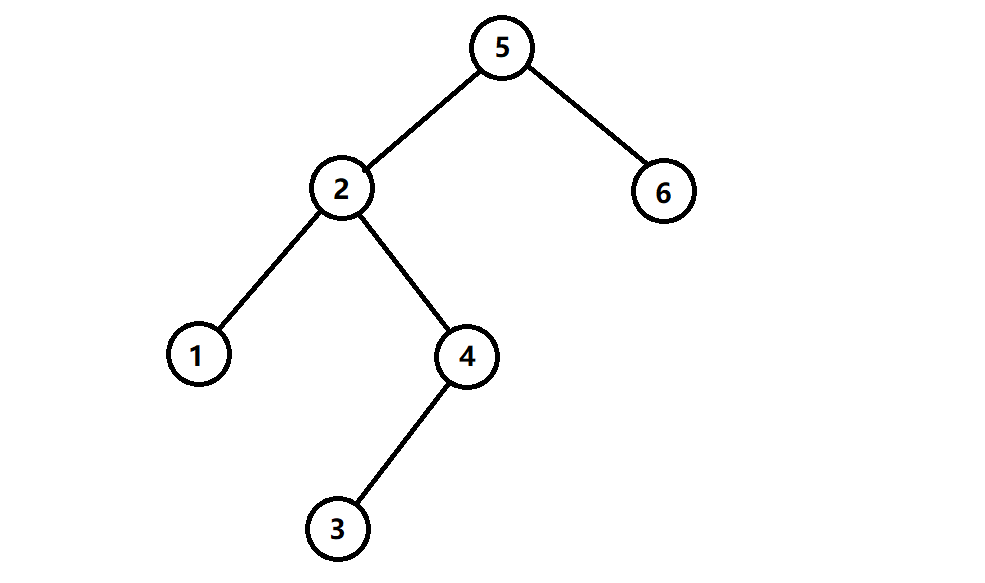
如上图所示,该二叉排序树的中序遍历序列为 1 2 3 4 5 6。
二、相关操作
1、二叉排序树的插入
二叉排序树作为一种动态树表,其特点是树的结构通常不是一次生成的,而是在查找过程中,当树中不存在关键字值等于给定值的结点时再进行插入的。
首先确定二叉排序树结点的数据结构及成员方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
public void add(TreeNode node) {
if (node.val < this.val) {
if (this.left == null) {
this.left = new TreeNode(node.val);
} else {
this.left.add(node);
}
}
if (node.val > this.val) {
if (this.right == null) {
this.right = new TreeNode(node.val);
} else {
this.right.add(node);
}
}
}
}
|
注:上面的算法忽略了当插入的值等于当前结点的情况,原因是二叉排序树一般用于当表中元素的值各不相同的情况时,如果在二叉排序树中插入多个相同值的结点时会影响查询的效率。
然后创建BinarySortTree类,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
| class BinarySortTree {
private TreeNode root;
public void insertNode(int value) {
if (root == null) {
root = new TreeNode(value);
} else {
root.add(new TreeNode(value));
}
}
}
|
之后在主方法中创建BinarySortTree类并调用其中的insertNode方法即可实现二叉排序树的插入。
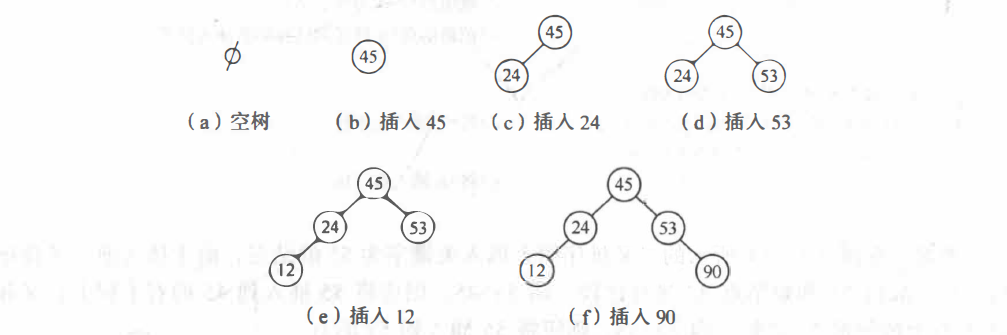
例如,现在有一个数组为 { 45, 24, 53, 45, 12, 24, 90 },则按上述算法生成二叉排序树的过程如下:
2、二叉排序树的查找
二叉排序树的查找是从根结点开始,沿某个分支逐层向下比较的过程。若二叉排序树非空,先将给定值与根结点的关键字比较,若相等,则查找成功;若不等,如果小于根结点的关键字,则在根结点的左子树上查找,否则在根结点的右子树上查找。这是一个递归的过程。
首先在TreeNode类中添加以下成员方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public TreeNode search(int value) {
if (this.val == value) {
return this;
} else if (this.val > value && this.left != null) {
return this.left.search(value);
} else if (this.val < value && this.right != null) {
return this.right.search(value);
} else {
return null;
}
}
|
然后在BinarySortTree类中添加以下成员方法:
1
2
3
4
5
6
7
| public TreeNode searchNode(int value) {
if (this.root != null) {
return root.search(value);
} else {
return null;
}
}
|
之后在主方法中调用BinarySortTree类的searchNode方法即可实现二叉排序树的查找。
3、二叉排序树的删除
在二叉排序树中删除一个结点时,不能把以该结点为根的子树上的结点都删除,必须先把被删除结点从存储二叉排序树的链表上移除,将因删除结点而断开的二叉链表重新链接起来,同时确保二叉排序树的性质不会丢失。下面将介绍在以下三种情况下删除结点的方法。
(1)删除叶子结点
如果被删除的结点是叶子节点,则直接删除,不会破坏二叉排序树的性质。在使用代码实现之前,我们需要分析一下算法的实现过程:
- 首先需要找到要删除的结点和它的父结点(如果存在的话)。
- 判断要删除的结点是其父结点的左子结点还是右子结点,并根据情况进行删除。
由上面的分析可知,我们需要在原有代码的基础上实现一个可以查找目标结点的父结点的方法,在TreeNode类中添加以下成员方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public TreeNode searchParent(int value) {
if ((this.left != null && this.left.val == value)
|| (this.right != null && this.right.val == value)) {
return this;
} else {
if (this.left != null && value < this.val) {
return this.left.searchParent(value);
} else if (this.right != null && value > this.val){
return this.right.searchParent(value);
} else {
return null;
}
}
}
|
在BinarySortTree类中添加以下成员方法:
1
2
3
4
5
6
7
| public TreeNode searchParent(int value) {
if (root != null) {
return root.searchParent(value);
} else {
return null;
}
}
|
下面我们将实现删除叶子结点的方法,在BinarySortTree类中添加如下成员方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public void deleteNode(int value) {
TreeNode target = searchNode(value);
if (target == null) {
return;
}
TreeNode parent = searchParent(value);
if (parent == null) {
root = null;
return;
}
if (target.left == null && target.right == null) {
if (target == parent.left) {
parent.left = null;
return;
}
if (target == parent.right) {
parent.right = null;
return;
}
}
}
|
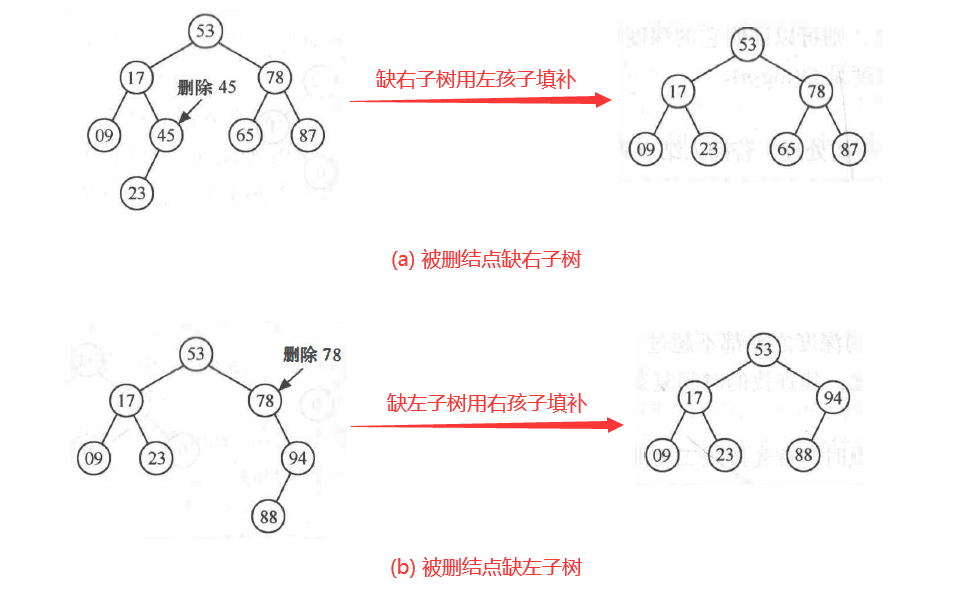
(2)删除只有一个子结点的结点
若被删除的结点只有一颗左子树或右子树,则让该结点的子树成为父结点的子树,替代该结点的位置。
在BinarySortTree类中添加如下成员方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| if (target.left == null && target.right == null) {
} else if (target.left != null && target.right != null) {
} else {
if (target.left != null) {
if (target == parent.left) {
parent.left = target.left;
} else {
parent.right = target.left;
}
} else {
if (target == parent.left) {
parent.left = target.right;
} else {
parent.right = target.right;
}
}
}
|
上述算法删除只有一个子结点的结点的过程如下图所示:
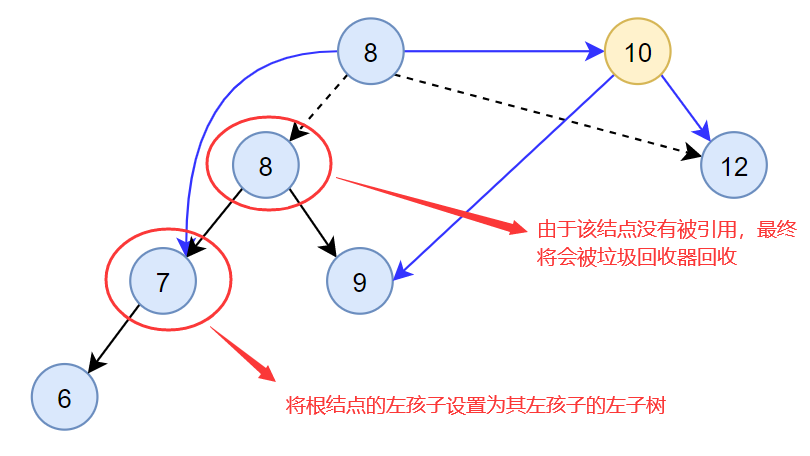
(3)删除有两个子结点的结点
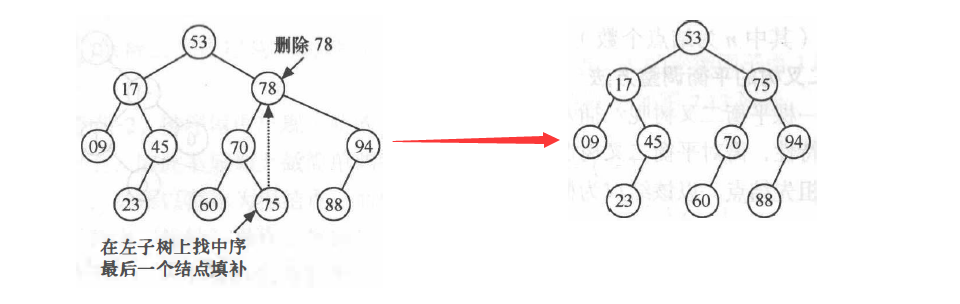
若被删除的结点有左、右两颗子树,则令该结点的直接后继(或直接前驱)替代该结点,然后从二叉排序树中删除这个直接后继(或直接前驱),这样就转换成了第一或第二种情况。
1
2
3
4
5
6
7
8
9
10
| if (target.left == null && target.right == null) {
...
} else if (target.left != null && target.right != null) {
int val = delRightSubTreeFirstNodeByInOrder(target.right);
target.val = val;
} else {
}
|
其中获取右子树中序第一个子结点的方法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| public int delRightSubTreeFirstNodeByInOrder(TreeNode node) {
TreeNode target = node;
while (target.left != null) {
target = target.left;
}
int value = target.val;
deleteNode(value);
return value;
}
|
上述算法删除有两个子结点的结点的过程如下图所示:
三、算法分析
二叉排序树的查找效率,主要取决于树的高度。若二叉排序树的左、右子树的高度之差的绝对值不超过 1,则这样的二叉排序树称为平衡二叉树,它的平均查找长度为$O(log_2n)$。若二叉排序树是一个只有右(左)孩子的单支树(类似于有序的单链表),则其平均查找长度为$O(n)$。
从查找过程看,二叉排序树与二分查找相似。就平均时间性能而言,二叉排序树上的查找和二分查找差不多。但二分查找的判定树唯一,而二叉排序树的查找不唯一,相同的关键字其插入顺序不同可能生成不同的二叉排序树,如下图所示:

就维护表的有序性而言,二叉排序树无需移动结点,只需修改指针即可完成插入和删除操作,平均执行时间为$O(log_2n)$。二叉查找的对象是有序顺序表,若有插入和删除结点的操作,所花的代价是$O(n)$。当有序表是静态查找表时,宜用顺序表作为其存储结构,而采用二分查找实现其查找操作;若有序表是动态查找表,则应选择二叉排序树作为其逻辑结构。